

Mistral Small, Gemma 2, Qwen 2.5, Mistral Nemo, LLama3 dan Phi - Uji LLM
Putaran berikutnya uji LLM
Tidak lama yang lalu telah dirilis. Mari kita mengejar dan uji bagaimana kinerja Mistral Small dibandingkan dengan LLM lainnya.
Putaran berikutnya uji LLM
Tidak lama yang lalu telah dirilis. Mari kita mengejar dan uji bagaimana kinerja Mistral Small dibandingkan dengan LLM lainnya.

Kode Python untuk reranking RAG

Model AI baru yang menakjubkan untuk menghasilkan gambar dari teks
Baru-baru ini Black Forest Labs mempublikasikan serangkaian model AI teks-ke-gambar yang dikatakan memiliki kualitas output yang jauh lebih tinggi. Mari coba model tersebut

Membandingkan dua mesin pencari AI self-hosted
Makanan yang luar biasa juga memberikan kesenangan bagi mata Anda. Namun, dalam posting ini kita akan membandingkan dua sistem pencarian berbasis AI, Farfalle dan Perplexica.
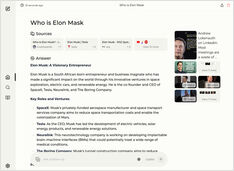
Menjalankan layanan gaya copilot secara lokal? Mudah!
Itu sangat menarik! Alih-alih memanggil copilot atau perplexity.ai dan memberi tahu seluruh dunia apa yang Anda cari, sekarang Anda dapat menjalankan layanan serupa di PC atau laptop Anda sendiri!
Tidak terlalu banyak pilihan, tetapi tetap....
Saat saya mulai bereksperimen dengan LLM, UI-nya sedang dalam pengembangan aktif dan sekarang beberapa dari mereka benar-benar bagus.

Menguji deteksi kesalahan logika
Baru-baru ini kita melihat beberapa LLM baru yang dirilis. Masa yang menarik. Mari kita uji dan lihat bagaimana mereka berperforma saat mendeteksi fallasi logis.

Memerlukan beberapa eksperimen tetapi
Masih ada beberapa pendekatan umum bagaimana cara menulis prompt yang baik agar LLM tidak bingung mencoba memahami apa yang Anda inginkan darinya.

8 versi LLM llama3 (Meta+) dan 5 versi LLM phi3 (Microsoft)
Menguji bagaimana model dengan jumlah parameter yang berbeda dan kuantisasi berperilaku.

Berkas model LLM Ollama memakan banyak ruang.
Setelah memasang ollama lebih baik mengonfigurasi ulang ollama untuk menyimpannya di lokasi baru segera. Jadi setelah kita menarik model baru, tidak akan didownload ke lokasi lama.

Mari uji kecepatan LLM pada GPU versus CPU
Membandingkan kecepatan prediksi beberapa versi LLMs: llama3 (Meta/Facebook), phi3 (Microsoft), gemma (Google), mistral (open source) pada CPU dan GPU.

Mari kita uji kualitas deteksi fallasi logis dari berbagai LLM.
Di sini saya membandingkan beberapa versi LLM: Llama3 (Meta), Phi3 (Microsoft), Gemma (Google), Mistral Nemo (Mistral AI), dan Qwen (Alibaba).