
Model Qwen3 Embedding & Reranker di Ollama: Kinerja Terbaik di Kelasnya
LLM baru yang menarik tersedia di Ollama
Model Qwen3 Embedding dan Reranker adalah rilis terbaru dalam keluarga Qwen, yang dirancang khusus untuk tugas pemrosesan teks lanjutan, pencarian, dan pengurutan ulang.
Kebahagiaan untuk mata
Model Qwen3 Embedding dan Reranker mewakili kemajuan signifikan dalam pemrosesan bahasa alami (NLP) multibahasa, menawarkan kinerja terbaik dalam tugas embedding dan pengurutan ulang teks. Model-model ini, yang merupakan bagian dari seri Qwen yang dikembangkan oleh Alibaba, dirancang untuk mendukung berbagai aplikasi, mulai dari pencarian semantik hingga pencarian kode. Meskipun Ollama adalah platform open-source populer untuk hosting dan penggunaan model bahasa besar (LLM), integrasi model Qwen3 dengan Ollama tidak secara eksplisit dijelaskan dalam dokumentasi resmi. Namun, model-model ini dapat diakses melalui Hugging Face, GitHub, dan ModelScope, memungkinkan penggunaan lokal melalui Ollama atau alat serupa.
Contoh penggunaan model-model ini
Silakan lihat contoh kode dalam Go menggunakan ollama dengan model-model ini:
- Pengurutan ulang dokumen teks dengan Ollama dan Qwen3 Embedding model - dalam Go
- Pengurutan ulang dokumen teks dengan Ollama dan Qwen3 Reranker model - dalam Go
Ringkasan Model Qwen3 Embedding dan Reranker Baru di Ollama
Model-model ini sekarang tersedia untuk dideploy di Ollama dalam berbagai ukuran, memberikan kinerja terbaik dan fleksibilitas untuk berbagai aplikasi terkait bahasa dan kode.
Fitur dan Kemampuan Utama
-
Ukuran Model dan Fleksibilitas
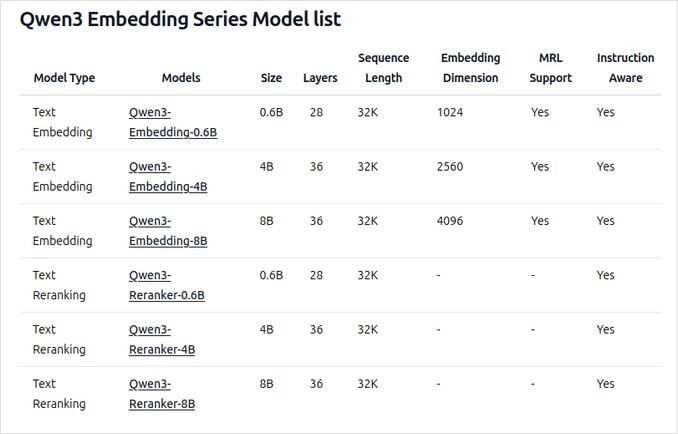
- Tersedia dalam beberapa ukuran: 0,6B, 4B, dan 8B parameter untuk tugas embedding dan pengurutan ulang.
- Model embedding 8B saat ini berada di peringkat No.1 leaderboard multibahasa MTEB (per 5 Juni 2025, dengan skor 70,58).
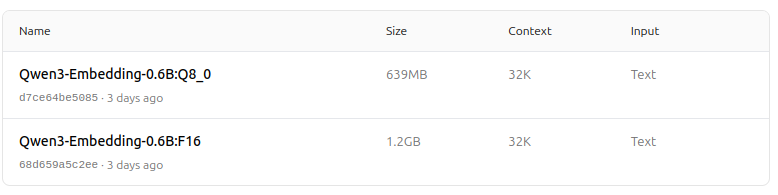
- Mendukung berbagai opsi kuantisasi (Q4, Q5, Q8, dll.) untuk menyeimbangkan kinerja, penggunaan memori, dan kecepatan. Q5_K_M disarankan untuk kebanyakan pengguna karena mempertahankan sebagian besar kinerja model sambil tetap efisien dalam penggunaan sumber daya.
-
Arsitektur dan Pelatihan
- Dibangun berdasarkan fondasi Qwen3, memanfaatkan arsitektur dual-encoder (untuk embedding) dan cross-encoder (untuk pengurutan ulang).
- Model embedding: Memproses segmen teks tunggal, mengekstrak representasi semantik dari state tersembunyi akhir.
- Model pengurutan ulang: Mengambil pasangan teks (misalnya, query dan dokumen) dan menghasilkan skor relevansi menggunakan pendekatan cross-encoder.
- Model embedding menggunakan paradigma pelatihan tiga tahap: pre-training kontrasif, pelatihan terawasi dengan data berkualitas tinggi, dan penggabungan model untuk generalisasi dan adaptasi optimal.
- Model pengurutan ulang dilatih langsung dengan data berkualitas tinggi untuk efisiensi dan efektivitas.
-
Dukungan Multibahasa dan Multitugas
- Mendukung lebih dari 100 bahasa, termasuk bahasa pemrograman, memungkinkan kemampuan pencarian multibahasa, lintas bahasa, dan kode yang kuat.
- Model embedding memungkinkan definisi vektor yang fleksibel dan instruksi pengguna yang ditentukan sendiri untuk menyesuaikan kinerja untuk tugas atau bahasa tertentu.
-
Kinerja dan Kasus Penggunaan
- Hasil terbaik dalam pencarian teks, pencarian kode, klasifikasi, pengelompokan, dan penambangan bitext.
- Model pengurutan ulang unggul dalam berbagai skenario pencarian teks dan dapat digabungkan secara mulus dengan model embedding untuk pipeline pencarian end-to-end.
Cara Menggunakan di Ollama
Anda dapat menjalankan model-model ini di Ollama dengan perintah seperti:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Pilih versi kuantisasi yang paling sesuai dengan kebutuhan perangkat keras dan kinerja Anda.
Tabel Ringkasan
| Jenis Model | Ukuran yang Tersedia | Keunggulan Utama | Dukungan Multibahasa | Opsi Kuantisasi |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Skor MTEB terbaik, fleksibel, efisien, SOTA | Ya (100+ bahasa) | Q4, Q5, Q6, Q8, dll. |
| Reranker | 0,6B, 4B, 8B | Unggul dalam relevansi pasangan teks, efisien, fleksibel | Ya | F16, Q4, Q5, dll. |
Berita Menarik!
Model Qwen3 Embedding dan Reranker di Ollama mewakili lonjakan signifikan dalam kemampuan pencarian teks dan kode multibahasa dan multitugas. Dengan opsi deployment yang fleksibel, kinerja benchmark yang kuat, dan dukungan untuk berbagai bahasa dan tugas, mereka sangat cocok untuk lingkungan penelitian dan produksi.
Kebun Model - Kebahagiaan untuk mata sekarang
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
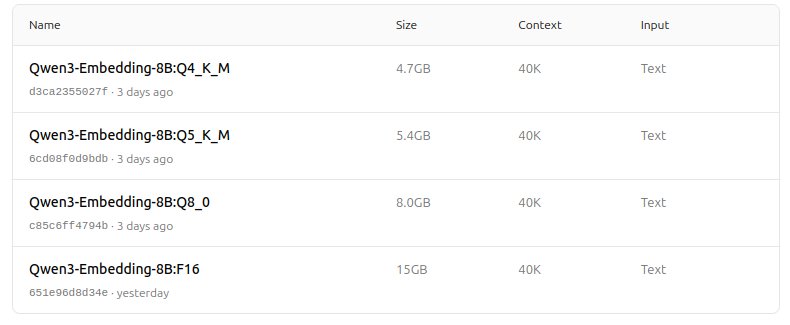
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
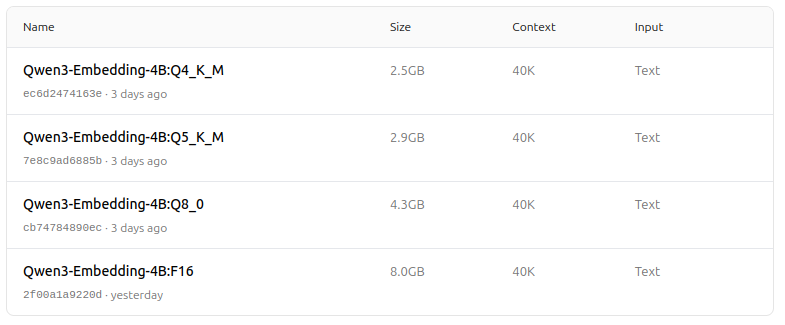
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
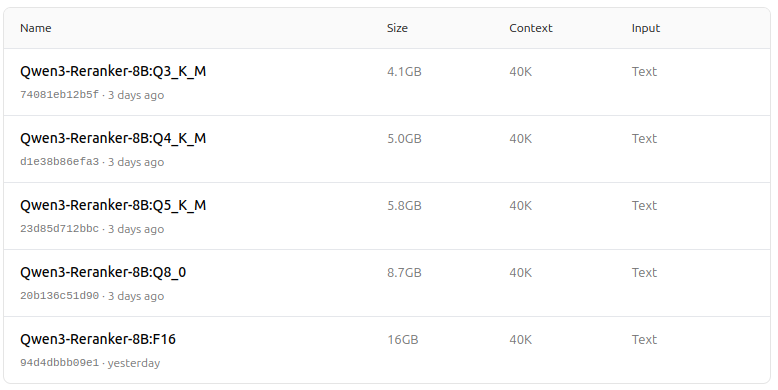
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
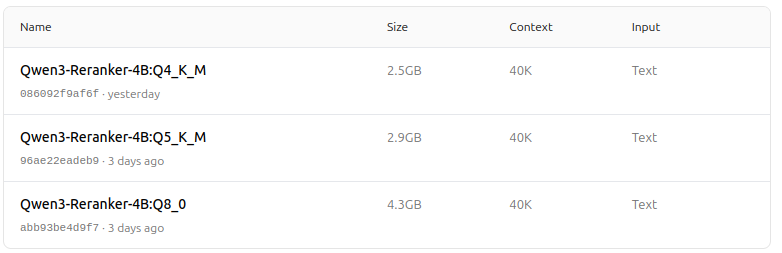
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
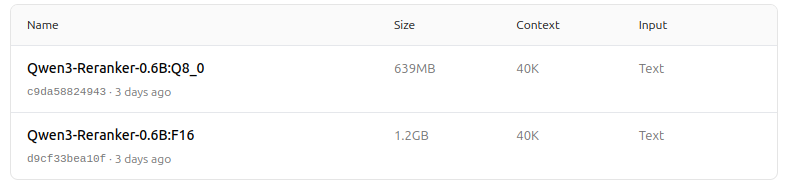
Bagus!
Tautan yang Berguna
- Pengurutan ulang dokumen teks dengan Ollama dan Qwen3 Embedding model - dalam Go
- Pengurutan ulang dokumen teks dengan Ollama dan Qwen3 Reranker model - dalam Go
- Ollama cheatsheet
- Pindahkan Model Ollama ke Drive atau Folder Berbeda
- Self-hosting Perplexica - dengan Ollama
- Uji: Bagaimana Ollama Menggunakan Kinerja dan Core Efisien Intel CPU
- Perbandingan Kecepatan Model LLM
- Perbandingan Kemampuan Penyusunan Ulang LLM
- Pemasok LLM Cloud
- Bagaimana Ollama Mengelola Permintaan Paralel
- Perbandingan Kualitas Terjemahan Halaman Hugo - LLMs di Ollama
